unCLIPモデルの例
1分以内
unCLIPモデルは、特別に調整されたSDモデルのバージョンで、テキストプロンプトに加えて画像コンセプトを入力として受け取ることができます。画像はこれらのモデルに付属するCLIPVisionによってエンコードされ、サンプリング時に抽出されたコンセプトがメインモデルに渡されます。
基本的に、プロンプトの中で画像を使用できるようになります。
以下は、ComfyUIでの使用方法です(これをComfyUIにドラッグしてワークフローを取得できます):
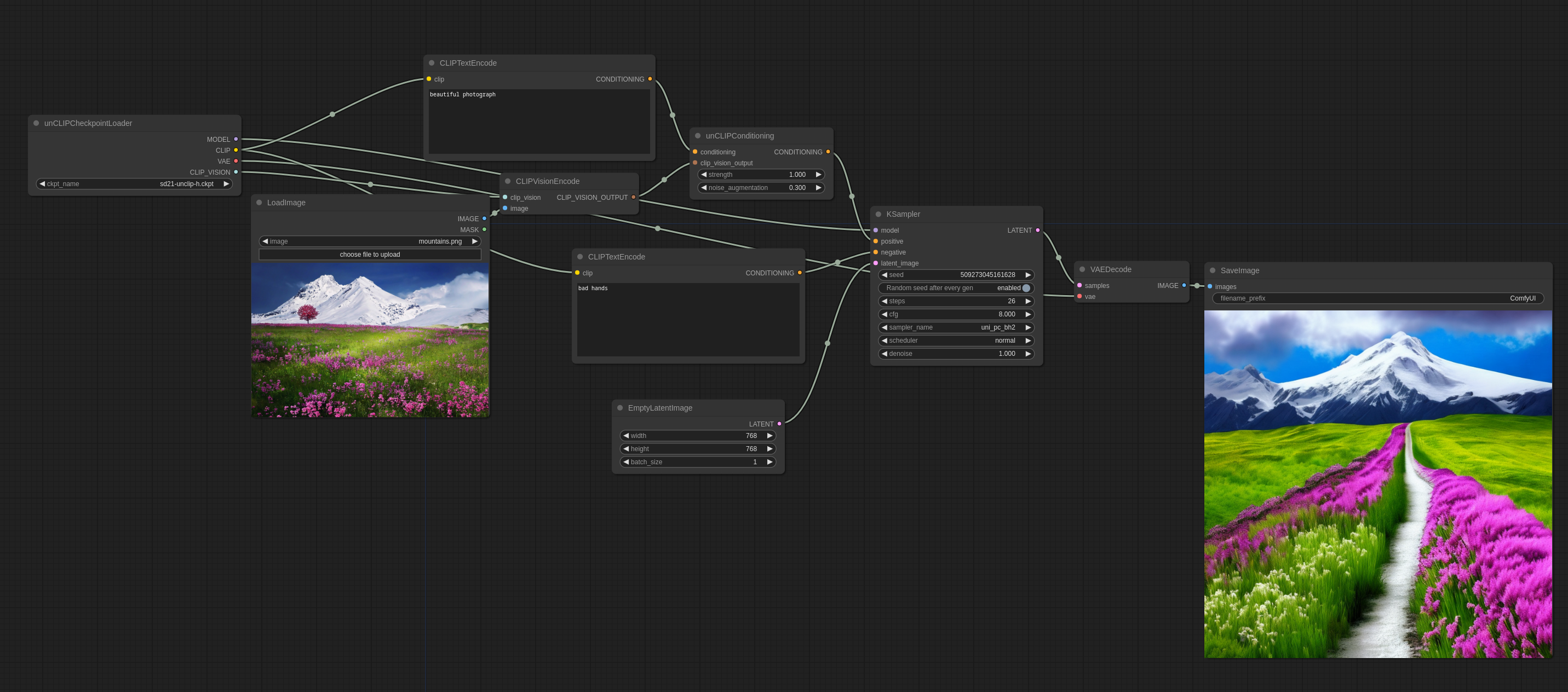
noise_augmentationは、モデルが画像コンセプトにどれだけ厳密に従うかを制御します。値が低いほど、コンセプトに忠実になります。
strengthは、画像に対する影響の強さです。
複数の画像を次のように使用することもできます:
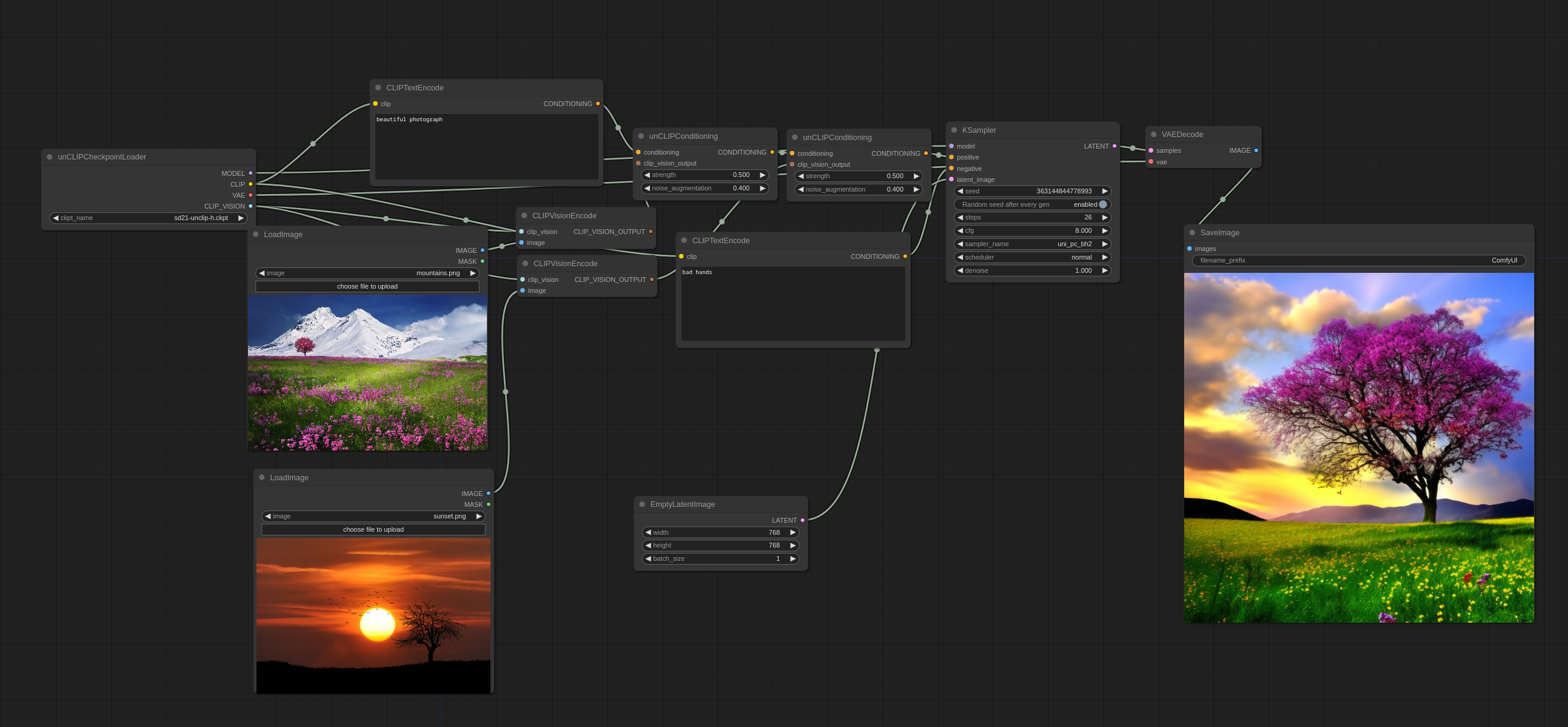
従来の意味で画像をブレンドするのではなく、実際に両方から一部のコンセプトを選び、一貫性のある画像を作成していることに気づくでしょう。
入力画像:


公式のunCLIPチェックポイントはこちらで見つけることができます。
既存の768-vチェックポイントからいくつかの巧妙なマージを通じて作成したunCLIPチェックポイントは、こちら(WD1.5 beta 2ベース)とこちら(illuminati Diffusionベース)で見つけることができます。
より高度なワークフロー
unCLIPチェックポイントを使用する良い方法は、2段階のワークフローの最初のステップで使用し、2番目のステップで1.xモデルに切り替えることです。以下の画像はこのように生成されました。(ComfyUIにロードしてワークフローを取得できます):
