unCLIP 模型示例
大约 1 分钟
unCLIP 模型是特别调整的 SD 模型版本,它们除了你的文本提示外,还能接收图像概念作为输入。图像通过这些模型附带的 CLIPVision 编码,然后在采样时将其提取的概念传递给主模型。
它基本上让你能在你的提示中使用图像。
这里是如何在 ComfyUI 中使用它的方法(你可以将此拖入 ComfyUI 以获得工作流程):
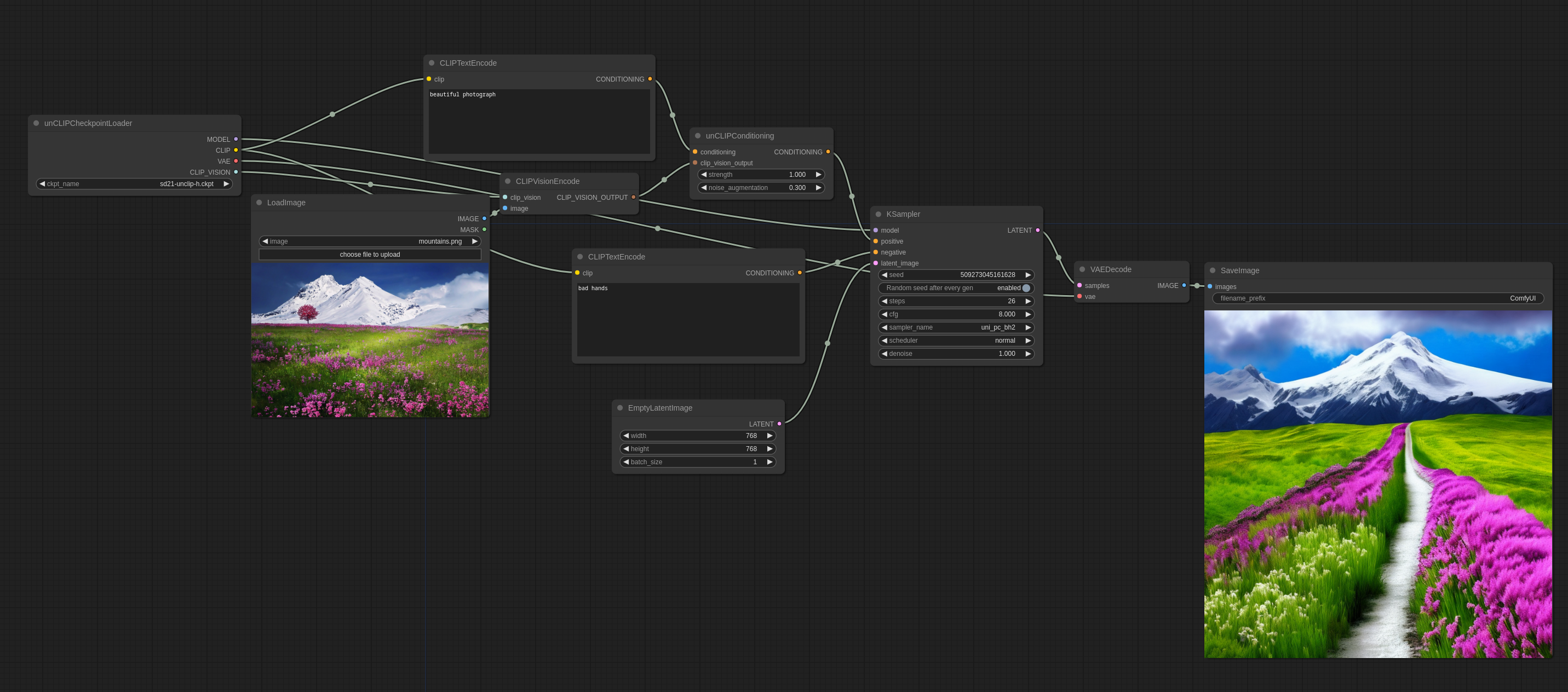
noise_augmentation 控制模型将如何紧密地跟随图像概念。值越低,它越会跟随概念。
strength 是它将对图像的影响力度。
可以像这样使用多个图像:
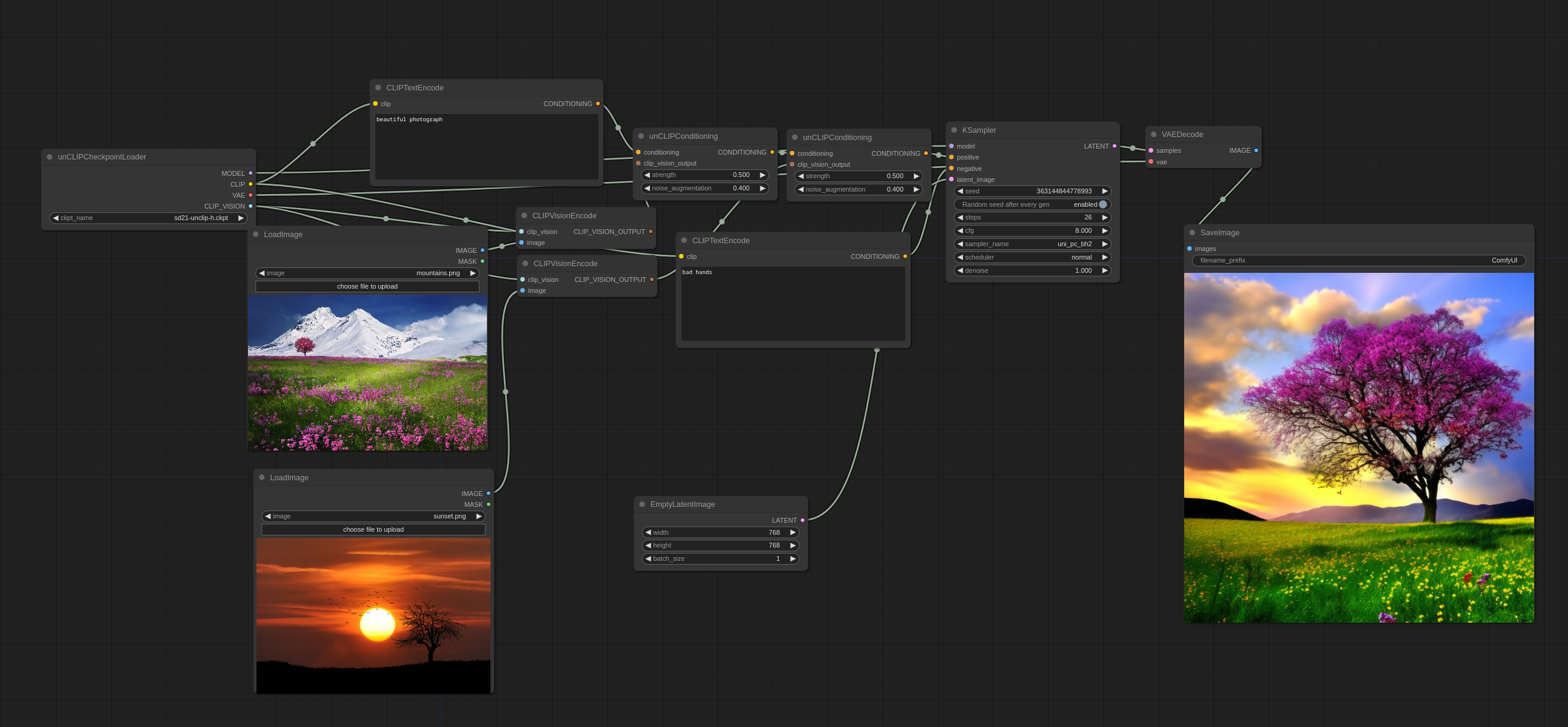
你会注意到它并不是以传统意义上混合图像,而是实际上从两者中挑选一些概念并制作出一个连贯的图像。
输入图像:


你可以在这里找到官方的 unCLIP 检查点
你可以在这里(基于 WD1.5 beta 2)和这里(基于 illuminati Diffusion)找到我从一些现有的 768-v 检查点通过一些巧妙的合并制作的一些 unCLIP 检查点
更高级的工作流程
使用 unCLIP 检查点的一个好方法是将它们用于两步工作流程的第一步,然后切换到 1.x 模型进行第二步。以下图像就是这样生成的。(你可以将其加载到 ComfyUI 中以获得工作流程):
